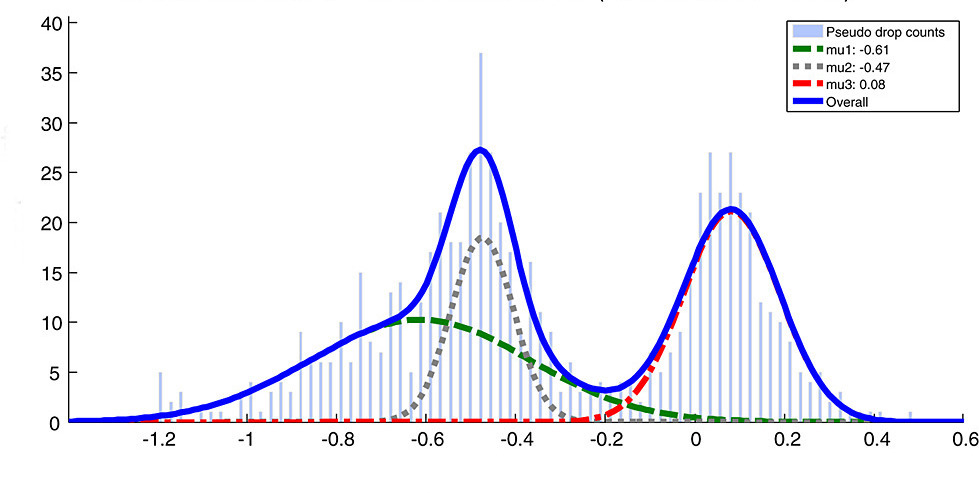
In this project we employ Sklearn's pipelines to compare performances two robust models for NLP : Multinomial Naive Bayes and the Random Forests.
Data: Yelp Review Data Set from Kaggle.
** Data Head **
| business_id | date | review_id | stars | text | type | user_id | cool | useful | funny | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9yKzy9PApeiPPOUJEtnvkg | 2011-01-26 | fWKvX83p0-ka4JS3dc6E5A | 5 | My wife took me here on my birthday for breakf... | review | rLtl8ZkDX5vH5nAx9C3q5Q | 2 | 5 | 0 |
| 1 | ZRJwVLyzEJq1VAihDhYiow | 2011-07-27 | IjZ33sJrzXqU-0X6U8NwyA | 5 | I have no idea why some people give bad review... | review | 0a2KyEL0d3Yb1V6aivbIuQ | 0 | 0 | 0 |
| 2 | 6oRAC4uyJCsJl1X0WZpVSA | 2012-06-14 | IESLBzqUCLdSzSqm0eCSxQ | 4 | love the gyro plate. Rice is so good and I als... | review | 0hT2KtfLiobPvh6cDC8JQg | 0 | 1 | 0 |
| 3 | _1QQZuf4zZOyFCvXc0o6Vg | 2010-05-27 | G-WvGaISbqqaMHlNnByodA | 5 | Rosie, Dakota, and I LOVE Chaparral Dog Park!!... | review | uZetl9T0NcROGOyFfughhg | 1 | 2 | 0 |
| 4 | 6ozycU1RpktNG2-1BroVtw | 2012-01-05 | 1uJFq2r5QfJG_6ExMRCaGw | 5 | General Manager Scott Petello is a good egg!!!... | review | vYmM4KTsC8ZfQBg-j5MWkw | 0 | 0 | 0 |
** Crude Data Metrics **
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 10 columns):
business_id 10000 non-null object
date 10000 non-null object
review_id 10000 non-null object
stars 10000 non-null int64
text 10000 non-null object
type 10000 non-null object
user_id 10000 non-null object
cool 10000 non-null int64
useful 10000 non-null int64
funny 10000 non-null int64
dtypes: int64(4), object(6)
memory usage: 781.3+ KB
| stars | cool | useful | funny | |
|---|---|---|---|---|
| count | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 |
| mean | 3.777500 | 0.876800 | 1.409300 | 0.701300 |
| std | 1.214636 | 2.067861 | 2.336647 | 1.907942 |
| min | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 3.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 4.000000 | 0.000000 | 1.000000 | 0.000000 |
| 75% | 5.000000 | 1.000000 | 2.000000 | 1.000000 |
| max | 5.000000 | 77.000000 | 76.000000 | 57.000000 |
** Data Exploration **
FacetGrid from the seaborn library to create a grid of 5 histograms of text length based off of the star ratings.
<seaborn.axisgrid.FacetGrid at 0x7facdee80410>

Boxplot of text length for each star category.
<matplotlib.axes._subplots.AxesSubplot at 0x7facde8a7210>

Countplot of the number of occurrences for each type of star rating.
<matplotlib.axes._subplots.AxesSubplot at 0x7fad1c8eded0>

** Group by the mean values of the numerical columns **
| cool | useful | funny | text length | |
|---|---|---|---|---|
| stars | ||||
| 1 | 0.576769 | 1.604806 | 1.056075 | 826.524700 |
| 2 | 0.719525 | 1.563107 | 0.875944 | 842.265372 |
| 3 | 0.788501 | 1.306639 | 0.694730 | 758.505133 |
| 4 | 0.954623 | 1.395916 | 0.670448 | 712.944129 |
| 5 | 0.944261 | 1.381780 | 0.608631 | 625.015583 |
Correlations in the grouped dataframe:
| cool | useful | funny | text length | |
|---|---|---|---|---|
| cool | 1.000000 | -0.743329 | -0.944939 | -0.857651 |
| useful | -0.743329 | 1.000000 | 0.894506 | 0.699895 |
| funny | -0.944939 | 0.894506 | 1.000000 | 0.843463 |
| text length | -0.857651 | 0.699895 | 0.843463 | 1.000000 |
**Visualizing correlations as heatmap **
<matplotlib.axes._subplots.AxesSubplot at 0x7fad1c77e8d0>

NLP Classification
For this project, We create dataframe called yelp_class that contains the columns of yelp dataframe but for only the 1 or 5 star reviews. We create two objects X and y. X will be the 'text' column of yelp_class and y will be the 'stars' column of yelp_class.Use the count verctorizer to vectorize X. We start with using simple Multinomial Naive bayes classifier on this X,y dataset
Model Evaluations
** Confusion matrix and classification report using MNB**
[[156 77]
[ 37 956]]
precision recall f1-score support
1 0.81 0.67 0.73 233
5 0.93 0.96 0.94 993
avg / total 0.90 0.91 0.90 1226
Really not bad. Now we use, TF-IDF weighing scheme on X and utilize Sckikit learn Pipeline method and evaluate on Multinomial Naive Bayes and Random Forest models
Model Evaluations
** Classification report and confusion matrix (Multinomial Naive Bayes):**
[[ 1 232] [ 0 993]]
precision recall f1-score support
1 1.00 0.00 0.01 233
5 0.81 1.00 0.90 993
avg / total 0.85 0.81 0.73 1226
** Classification report and confusion matrix (Random Forest):**
[[ 30 203]
[ 1 992]]
precision recall f1-score support
1 0.97 0.13 0.23 233
5 0.83 1.00 0.91 993
avg / total 0.86 0.83 0.78 1226
#TF-IDF with MNB prefromed worse. RF imporved recall for class 1. For this project, the model without TF-IDF weighing performed better.